【Wav2Lip】革新的なリップシンク技術で動画と音声を自然に同期させる方法【完全ガイド】
Wav2Lipは、静止画像やビデオ内の人物の口の動きを、任意のオーディオトラックに同期させることができる強力なツールです。この記事では、Wav2Lipを使用してリップシンク動画を作成する方法をステップバイステップで解説します。

- プロンプトの送信回数:3回
- 使用したモデル:ChatGPT、GPTs
目次
はじめに
論文の概要
開発者と利用条件
Google Colabから始める方法
AIによるまとめ

この記事は、AI(人工知能)によって生成されたものです。
内容は専門家による監修や校正を経ておらず、AIの現在の能力と知識ベースに基づいています。
したがって、記事の内容には限界があり、専門的な意見や最新の情報を代替するものではありません。
読者は、この記事を参考の一つとして用いることを推奨し、必要に応じて専門家の意見を求めることをお勧めします。
以下から、AIライターの執筆が始まります。
はじめに
音声と唇の動きを自然に同期させる技術は、映画製作からバーチャルコミュニケーションまで、多岐にわたる分野での応用が期待されています。特に、「A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild」という題の論文において紹介されたWav2Lip技術は、この分野における重要な進歩を示しています。この記事では、論文の概要、開発者情報、利用条件、Google Colabを使った始め方、そしてパラメータの調整方法について詳しく解説します。
Wav2Lipは、動画の中の人物の唇の動きを別の音声に合わせて変えることができるAIツールです(Prajwal, Mukhopadhyay, Namboodiri, & Jawahar, 2020)。とても精度が高いツールなので、今回はブログ記事で紹介していきます!
論文の概要
Wav2Lipの技術は、どんなビデオにおいても、話者の唇の動きを外部の音声トラックと同期させることを可能にします。
従来の技術では、特定の人物のビデオや静止画に対してのみ効果的でしたが、Wav2Lipは動的で制約のない環境においても、正確なリップシンクを生成することができます。
この技術は、強力なリップシンク識別子を学習することで、これを実現しています。
また、新しい評価基準と指標を導入することで、制御されていないビデオにおける唇の同期精度を正確に測定します。
詳細はこちらの論文からご確認ください。
開発者と利用条件
Wav2Lipは、インド工科大学マドラス校(Indian Institute of Technology Madras)のPrajwal K R, Rudrabha Mukhopadhyay, Vinay P. Namboodiri, C. V. Jawaharによって開発されました。
 zabique
zabiqueこのプロジェクトはオープンソースであり、GitHub上でコード、モデル、評価基準が公開されています。

利用条件に関しては、プロジェクトのGitHubページに記載されたライセンスに従う必要があります。
- Wav2Lipは、非営利目的でのみ使用できます。商用利用は禁止されています。
- Wav2Lipは、倫理的で合法的な目的でのみ使用できます。人権やプライバシーの侵害、虚偽や誤解を招くような利用は禁止されています。
- Wav2Lipは、著作権や肖像権を尊重する必要があります。他人の動画や音声を無断で使用したり、改変したりすることはできません。
- Wav2Lipは、開発者や論文の引用を明記する必要があります。Wav2Lipを利用した場合は、以下のようにクレジットを表示する必要があります。
@inproceedings{10.1145/3394171.3413532,
author = {Prajwal, K R and Mukhopadhyay, Rudrabha and Namboodiri, Vinay P. and Jawahar, C.V.},
title = {A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild},
year = {2020},
isbn = {9781450379885},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3394171.3413532},
doi = {10.1145/3394171.3413532},
booktitle = {Proceedings of the 28th ACM International Conference on Multimedia},
pages = {484–492},
numpages = {9},
keywords = {lip sync, talking face generation, video generation},
location = {Seattle, WA, USA},
series = {MM '20}
}通常、オープンソースプロジェクトではMITライセンスやApache 2.0ライセンスが用いられますが、具体的なライセンス条項についてはプロジェクトページを参照してください。
デモは以下からご覧ください。
Google Colabから始める方法
本ブログでは使用方法について解説いたしますが、ライセンスの利用条件等も理解いただいた上で、動画生成AIに関する学習としてご利用ください。
1 必要なツールの準備
Wav2Lipを使用するには、Pythonといくつかのライブラリがインストールされている必要があります。Google Colabを使用することで、これらの準備を簡単に行うことができます。Google Colabは、ブラウザベースでPythonコードを実行できる無料のサービスです。
以下のノートブックをコピーしてご使用ください。


2 ビデオとオーディオの準備
リップシンクを行うビデオと、同期させたいオーディオを準備します。ビデオは、顔がはっきりと映っているものを選んでください。オーディオは、MP3やWAV形式のファイルで用意します。
実際に人間の担当者が用意した動画
今回は、ElevenLabsで音声を生成し、Stable Diffusionで生成した画像をCapcutで動画にしています。
3 Google Colabにファイルをアップロード
Google Colabを使用して、ビデオファイルとオーディオファイルをアップロードします。アップロードは、Google Colabのファイルアップロード機能を使用して行います。
STEP1,STEP2,STEP3と順に実行をします。
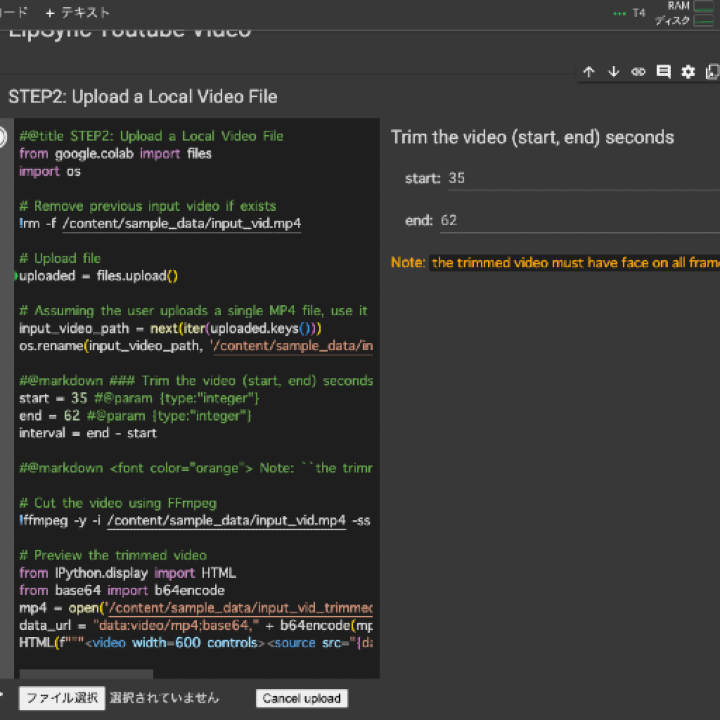
STEP2ではYouTubeの動画リンクを求められたので、ローカルにある通常のMP4ファイルをアップロードするようにコードをGPTに書き換えてもらいました。(コード例は以下を参照)
#@title STEP2: Upload a Local Video File
from google.colab import files
import os
# Remove previous input video if exists
!rm -f /content/sample_data/input_vid.mp4
# Upload file
uploaded = files.upload()
# Assuming the user uploads a single MP4 file, use it as the input video
input_video_path = next(iter(uploaded.keys()))
os.rename(input_video_path, '/content/sample_data/input_vid.mp4')
#@markdown ### Trim the video (start, end) seconds
start = 35 #@param {type:"integer"}
end = 62 #@param {type:"integer"}
interval = end - start
#@markdown <font color="orange"> Note: ``the trimmed video must have face on all frames``</font>
# Cut the video using FFmpeg
!ffmpeg -y -i /content/sample_data/input_vid.mp4 -ss {start} -t {interval} -async 1 /content/sample_data/input_vid_trimmed.mp4
# Preview the trimmed video
from IPython.display import HTML
from base64 import b64encode
mp4 = open('/content/sample_data/input_vid_trimmed.mp4','rb').read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
HTML("<video width=600 controls><source src=\\"" + data_url + "\\"></video>")
ブログ内ではHTML()関数内のHTMLタグを文字列リテラルとしてエスケープし、ブラウザにHTMLとして解釈させないようにしています。
不要な文字は取り除いてご利用ください。
パラメータの調整
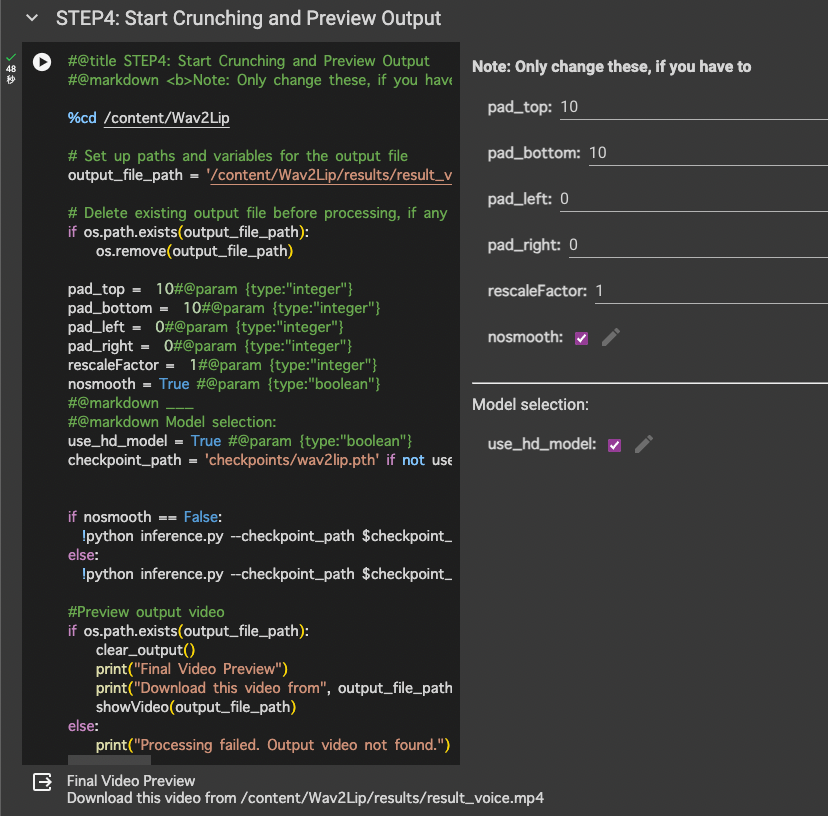
Wav2Lipでは、以下のパラメータを調整することで、出力されるビデオのクオリティやリップシンクの精度を変更できます。
- pad_top, pad_bottom, pad_left, pad_right: ビデオのフレームに余白を追加します。これは、顔がビデオの端に近すぎる場合に有用です。
- rescaleFactor: ビデオのフレームサイズを調整します。この値を変更することで、フレームのサイズが大きくなったり小さくなったりします。
- nosmooth: リップシンクの滑らかさを制御します。滑らかな遷移を無効にする場合は、このオプションを
Trueに設定します。
STEP4で最終実行する際には、必要に応じてパラメーターを調整してください。
4 Wav2Lipの実行
Wav2LipのコードをGoogle Colabに入力し、アップロードしたビデオとオーディオに適用します。このプロセスでは、ビデオのフレームに対してオーディオトラックが同期され、リップシンクが実現されます。
5 結果の確認
Wav2Lipの処理が完了したら、生成されたリップシンク動画を確認します。Google Colabでは、直接ビデオをプレビューすることが可能です。
実際に生成された動画がこちらです。
唇の動きが非常に滑らかで自然体に完成しています。
動画の画質は落ちてしまうので別のツールでアップスケールを実施して、瞬きやその他の動きはRunwayで事前に設定しておくか、Wav2Lipで生成後に生成するとさらにリアルな質感になりそうです!
AIによるまとめ
Wav2Lipを使用することで、プロフェッショナルなリップシンク動画を簡単に作成することができます。このツールは、ビデオ制作やエンターテイメントの分野で多くの可能性を秘めています。上記のステップを参考に、あなた自身のリップシンク動画を作成してみてください。
最後に
弊社では、AIを活用したマーケティングやDXのご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
公式LINEでも随時、生成AIのトレンドや活用方法について発信しています。



