未来を創る:Google I/O 2024のハイライト
Google I/O 2024は、AI技術の最新動向とGoogleのAI戦略に関する重要な発表が行われたイベントでした。このブログ記事では、Google I/O 2024で発表された内容についてご紹介します。
- プロンプトの送信回数:2回
- 使用したモデル:ChatGPT(GPT-4o),Perplexity, Claude3 Opus
AIとデジタルイノベーションでビジネスを変える時が来ました。
私たちと一緒に、効果的なマーケティングとDXの実現を目指しませんか?
弊社では、生成AI開発やバーチャルインフルエンサーの運用について無料相談を承っております。
お打ち合わせではなくチャットでのご相談もお待ちしております。

目次
Google I/O 2024年に発表された内容
Geminiに関する発表内容
生成AI系の発表内容
その他のハイライト
人間によるまとめ
この記事は、AI(人工知能)によって生成されたものです。
内容は専門家による監修や校正を経ておらず、AIの現在の能力と知識ベースに基づいています。
したがって、記事の内容には限界があり、専門的な意見や最新の情報を代替するものではありません。
読者は、この記事を参考の一つとして用いることを推奨し、必要に応じて専門家の意見を求めることをお勧めします。
以下から、AIライターの執筆が始まります。
Google I/O 2024年に発表された内容
今年のGoogle I/O 2024は、テクノロジー業界に多くの驚きと興奮をもたらしました。
Googleは、新しいAI機能において、多岐にわたる革新を披露しました。特に注目を集めたのは、画像・動画生成や進化したGoogle検索、そして強化されたGeminiです。これらの新機能は、私たちのデジタルライフをさらに便利で楽しいものにするでしょう。この記事では、Google I/O 2024のハイライトを詳しく紹介します。
公式はこちらから
OpenAIとGoogleの頂上決戦を見ている気分になリました。深夜ですが、OpenAIに続いて2日連続の発表にワクワクが止まらない担当者です。
それでは、早速内容を見ていきましょう。
Geminiに関連する発表
Gemini 1.5 Proがウェブアプリで提供開始
Gemini 1.5 ProがGoogle AI Studio および Vertex AI で利用できるようになっていましたが、翻訳、コーディング、推論などの主要なユースケース全体で一連の品質向上した上で、Gemini 1.5 Proが本日からGeminiのアプリ上で利用できるようです。


最大100万トークン(1500ページ相当)の情報を処理でき、Gemini Advancedでは複数のドキュメントを読み込ませることができるようになります。
アップデートが早いです...実際にGemini 1.5 Proを高評価している方も多くいらっしゃったので、これからどのくらい普及するかウォッチですね。
Gemini 1.5 flash
軽量化されたGemini 1.5 flashモデルは、モデルの応答時間の速度が最も重要となる、より狭いタスクや高頻度のタスク向けに最適化されているようです。こちらも、 100 万トークンのコンテキスト ウィンドウが付属しており、テキスト、画像、オーディオ、ビデオを入力が可能です!
In the coming weeks, we'll be adding new data analysis capabilities to Gemini Advanced. Just upload your spreadsheets and Gemini can analyze your data, make charts and uncover insights faster. #GoogleIO pic.twitter.com/oag2679HcP
— Google (@Google) May 14, 2024
公式ブログにはGoogle ドライブ経由で直接アップロード可能と記載がありますね。flashの詳細に関しては技術レポートで近々共有されるようです。
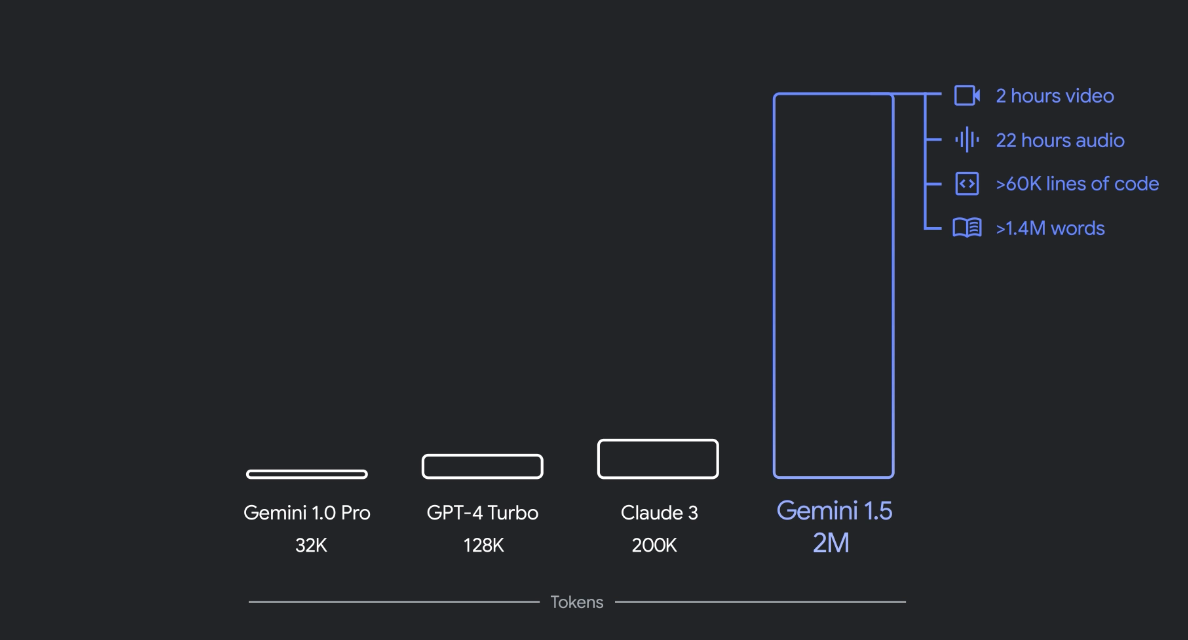
200万トークンのコンテクストウィンドウ
Gemini 1.5 ProはAPIを使用する開発者とGoogle Cloudの顧客向けに、200万トークンのコンテキスト ウィンドウも提供されています。

Gemini
Gemini for Google Workspace
Gmail でのメールの下書きからスプレッドシートでのプロジェクト計画の整理まで、人々や企業が Google アプリをさらに活用できるように支援します。Gemini 1.5 ProはGmail モバイル アプリに追加される予定です。
Geminiがメールの要約や受信トレイから分析情報を収集してくれるようです。
You can even ask Gemini in Sheets for help analyzing your expenses with Data Q&A. The ability to organize attachments in Drive, generate a sheet, and analyze data will roll out to Labs later this year. #GoogleIO pic.twitter.com/OCKqmUbUAv
— Google (@Google) May 14, 2024
現場普及にはWoekspaceの活用場面増加が一番ありがたい気がします。
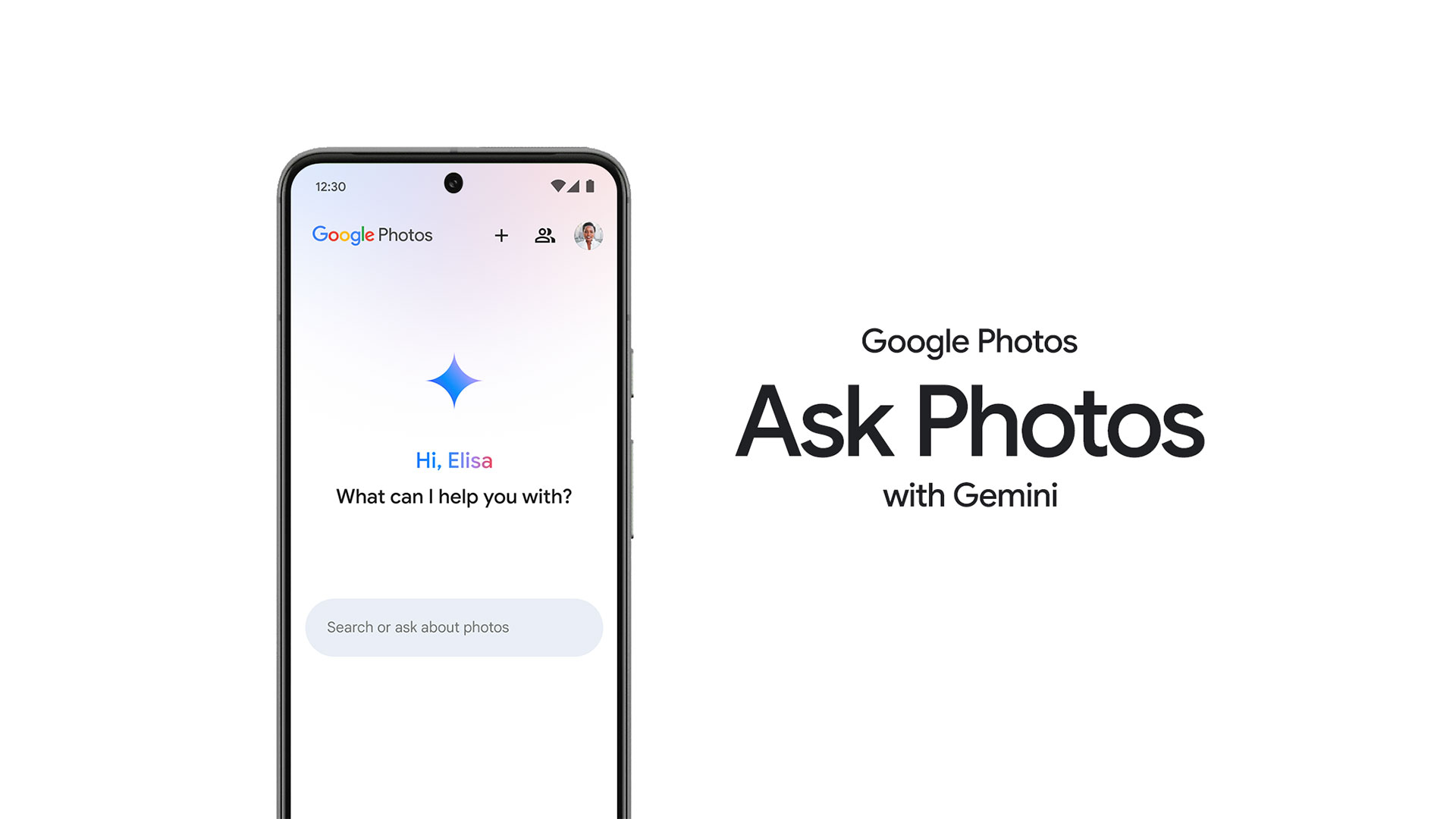
Ask Photos
Ask Photos を使用すると、「これまで訪れた各国立公園で一番良かった写真を見せて」のように、自然な方法で探しているものを尋ねることができます。
Gemini のマルチモーダル機能は、各写真で何が起こっているかを正確に理解するのに役立ち、必要に応じて画像内のテキストを読み取ることもできます。 Ask Photos は役立つ応答を作成し、返す写真とビデオを選択します。
Gems で Gemini をカスタマイズ
ジム仲間、副料理長、コーディング パートナー、クリエイティブ ライティング ガイドなど、思い描いたあらゆる Gem を作成できます。セットアップも簡単です。
Gemini は指示を受け取り、ワンクリックでそれを強化して、特定のニーズを満たす Gem を作成します。
Whether you need a yoga bestie or calculus tutor, in the coming months you’ll be able to customize Gemini, saving time when you have specific ways you interact with Gemini again and again. We’re calling these Gems. #GoogleIO pic.twitter.com/YQOHsUbMWE
— Google (@Google) May 14, 2024
カスタマイズ機能もつきましたね。他のGoogle機能を指示内に追加できる点は面白いですね。
Gemini Live
今後数か月以内に、Gemini との会話をより直観的にするために最先端の音声テクノロジーを使用する新しいモバイル会話エクスペリエンスである Live for Gemini を Advanced 加入者に公開します。
Gemini Live を使用すると、Gemini に話しかけて、応答できるさまざまな自然な音声の中から選択できます。他の会話と同じように、自分のペースで話したり、応答の途中で中断して質問を明確にしたりすることもできます。
This summer, we’re expanding Gemini’s multimodal capabilities — including the ability to have an in-depth two-way conversation using your voice. This new experience is called Live. #GoogleIO pic.twitter.com/eAZbaO5WKz
— Google (@Google) May 14, 2024
今年後半には、ライブ配信時にカメラを使用できるようになり、周囲で見ているものについての会話が可能になるとのことです。
生成AI系の発表
動画生成モデル「Veo」と実験ツールのVideoFX
1 分を超えることもある高品質の 1080p 解像度のビデオを生成可能なモデル「Veo」についてもデモ付きで公開されました。

Veoに関する詳細
Waitlist登録先
Veoが生成したデモ動画が多数載っているのですが、以下の注釈の記載が挑戦的で痺れました。
注: このページのすべてのビデオは Veo によって生成され、変更されていません。
✍️ Prompt: “A panning shot of a serene mountain landscape, the camera slowly revealing snow-capped peaks, granite rocks and a crystal-clear lake reflecting the sky.” pic.twitter.com/v3tZTzaEdA
— Google DeepMind (@GoogleDeepMind) May 14, 2024
動画生成において一貫性は大きな課題ですが、「ビデオフレーム間の一貫性」についてもVeoが不一致の出現を軽減して生成できると記載がありました。
画像生成モデル「Imagen 3」
画像生成AIとしては、Imagen 3が発表されました。

以下は生成結果として公開されている画像の一部です。


ImageFXのプライベート プレビューでクリエイターを選択するか、Waitlist王六で本日から利用可能みたいです。また、Imagen 3 は間もなくVertex AIに導入される予定なようです。
YouTubeと連携して音楽コミュニティとのコラボレーション
YouTube と提携し、素晴らしいミュージシャン、ソングライター、プロデューサーと協力しているそうです。これらのコラボレーションは、 AI 音楽生成の最も先進的なモデルであるLyriaを含む、当社の音楽生成テクノロジーの開発にも影響を与えています。
この取り組みの一環として、「 Music AI Sandbox」 と呼ばれる一連の音楽 AI ツールを開発しています、また、創造性のための新しい遊び場を開くように設計されており、人々が新しい楽器セクションをゼロから作成したり、新しい方法でサウンドを変換したりすることができます。
教育現場向けの「LearnLM」
LearnLM では、検索、YouTube、Gemini とのチャット時など、現在すでに使用している製品での学習エクスペリエンスを強化し、単に答えを与えるだけでなく理解を深められるようにしています。以下にいくつかの例を示します。
- Google 検索では、ボタンをタップして AI の概要を自分にとって最も役立つ形式 (言語を簡略化するか分解するかなど) に調整することで、複雑なトピックを理解できるようになります。
- Android では、 Circle to Search を使用して、携帯電話やタブレットから直接数学や物理の文章問題から抜け出すことができます。今年後半には、シンボリックな数式、図、グラフなどを含むさらに複雑な問題を解決できるようになります。
- Geminiとチャットする場合、間もなく、あらゆるトピックについて個人の専門家として機能できる Gemini のカスタム バージョンであるGemsを使用できるようになります。既成の Gem の 1 つである学習コーチは、クイズやゲームなどの役立つ練習アクティビティとともに、段階的な学習ガイダンスを提供することで、知識の構築をサポートします。 Gemini の学習コーチは今後数か月以内にリリースされ、Gemini Advanced を使用すると、独自の学習の好みに合わせてこの Gem をさらにカスタマイズできるようになります。
- YouTubeでは、会話型 AI ツールを使用して、学術ビデオを見ながら比喩的に「手を上げる」ことで、明確な質問をしたり、役立つ説明を得たり、学習内容に関するクイズに答えたりすることができます。これは、Gemini モデルのロングコンテキスト機能のおかげで、講義やセミナーなどの長い教育ビデオでも機能します。これらの機能は、米国の一部の Android ユーザーにすでに展開されています。

詳細はこちらから
書き出してみるとかなりの情報量の多さに圧倒されます。どう評価して使いこなしていくのか模索していきましょう。
その他のハイライト
Google 検索にGeminiモデルがカスタマイズ
生成 AI により、検索は想像以上のことを実行できるようになりました。そのため、リサーチから計画、ブレーンストーミングまで、気になったことや実行する必要があることを何でも質問でき、Google がその作業を引き受けます。
最も期待しているのは、Googleレンズに動画を送付して検索し、AIがリサーチして概要を生成してくれることです。一般的に最も使用されるのはGemini搭載のGoogle検索かもしれませんね...
And you’ll also be able to ask questions with video, right in Search. Coming soon. #GoogleIO pic.twitter.com/zFVu8yOWI1
— Google (@Google) May 14, 2024
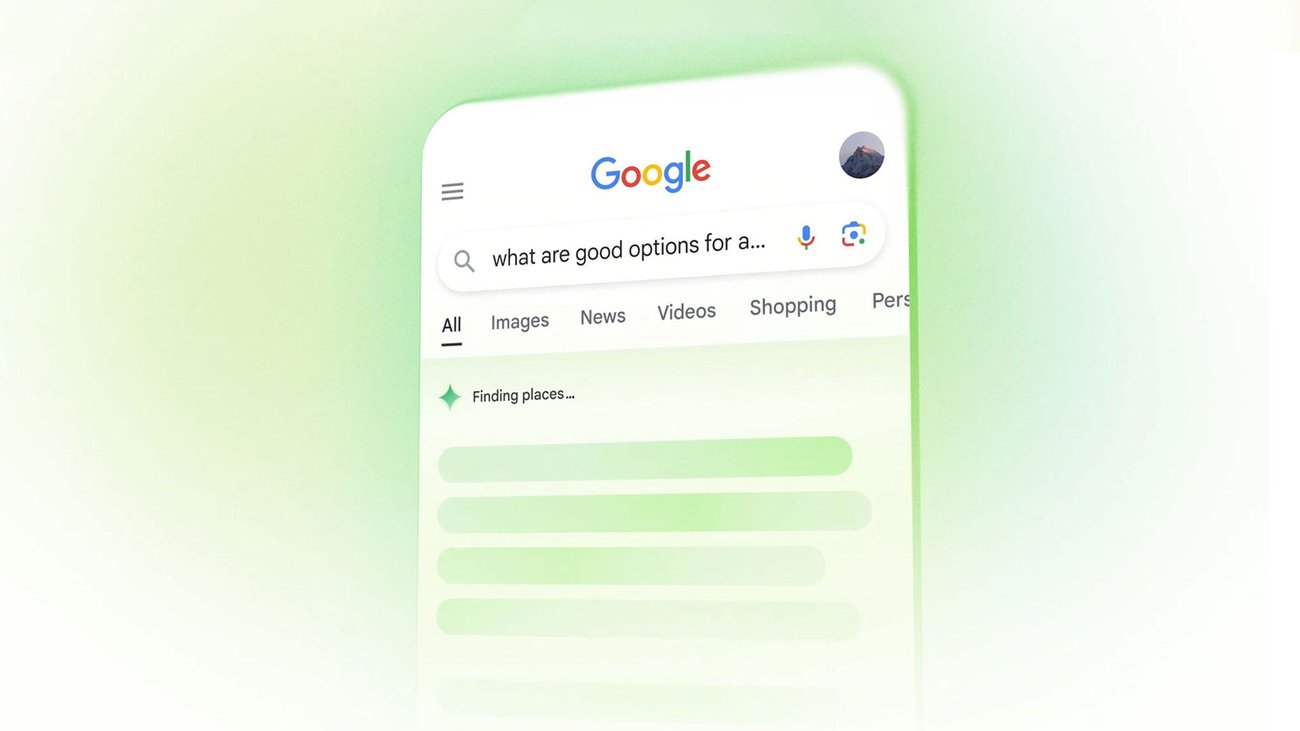
詳細はこちら
第 6 世代の Google Cloud TPU、Trillium
このハードウェアは、 Gemini 1.5 Flash、Imagen 3、Gemma 2などの新しいモデルを含む、本日 Google I/O で発表した多くのイノベーションをサポートしました。これらのモデルはすべて TPU でトレーニングされ、TPU を使用して提供されます。モデルの次のフロンティアを提供し、お客様も同様のことを実現できるようにするために、これまでで最もパフォーマンスが高くエネルギー効率の高い TPU である第 6 世代 TPU、Trillium を発表できることを嬉しく思います。

詳細はこちら
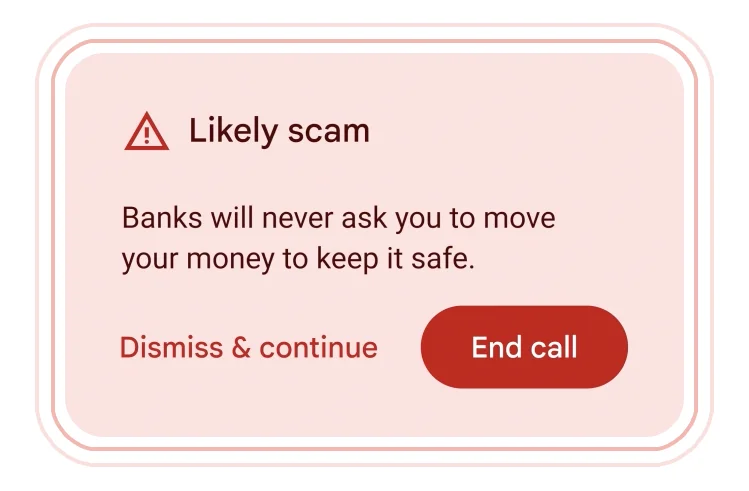
Project Astra : AIアシスタント
昨日公開されたOpenAIのデモのように、スマートフォンで映した動画を解析し(画像を認識し)音声で返答が返ってきています。
Google Mapを連想させるように風景から場所を特定していることも面白いのですが、途中であったメガネについての質問への回答、後半のおしゃれなグラスに対してのコメントがSNSでは多く発信されていました。
AndroidにおけるGoogle AI体験
画面に表示されている内容や使用しているアプリのコンテキストをさらによく理解できるようになったことで、生成された画像を Gmail、Google メッセージ、その他の場所にドラッグ アンドドロップしたり、「このビデオに質問」をタップして YouTube ビデオ内の特定の情報を検索したりできます。
詳細はこちら
また、今年後半の Pixel から、マルチモダリティを備えた最新モデル Gemini Nano を導入する予定です。これは、携帯電話がテキスト入力を処理できるだけでなく、光景、音、話し言葉などのコンテキスト内のより多くの情報を理解できることを意味します。
人間によるまとめ
OpenAI、Googleと連日発表が続きましたが、頂上決戦と感じられるように双方が同様の領域でアップデートであることに面白さを感じました。OpenAIのSora(発表はなかったが)とGoogleのVeo、リアルタイムに音声で回答結果をユーザーに伝えるUX、マルチモーダル機能等、両社が同様の領域で新機能をリリースしていく予定ですが、今後はユーザーが目的に応じて最適なモデル選択をして活用していきたいですね。ただ新しいものを利用するのではなく、性能を評価して実用していくことがさらに迫られています。
また、生成AIに関しては一部のアーリー層が利用していましたが、今後はさらにマス層の利用が増加していくことを考慮すると企業側の整備だけでなく法律の整備も思ったより早く進行しそうですね。
リアルタイムで視聴しブログ記事を書いていた担当者ですが、以下のツイート内容がこの2日間の内容がまとまっていると感じたのでご共有いたします。
Google I/O. Some thoughts: the model seems to be multimodal in, but not multimodal out. Imagen-3 and music gen models are still detached from Gemini as standalone components. Merging all modality I/O natively is the inevitable future:
— Jim Fan (@DrJimFan) May 14, 2024
- enables tasks like "use a more robotic… pic.twitter.com/MsFk1pFoqe
GPT-4oは完璧ではないが、形式は正しい。多くのファイル形式をネイティブでサポートする必要がある。Googleは検索ボックスにAIを統合する努力をしており、これが強みとなる。Geminiは最高のモデルでなくても、最も多く使用されるモデルになる可能性がある。
最後に
弊社では、AIを活用したマーケティングやDXのご相談を承っておりますので、ご興味がある方はぜひご連絡ください。



